A transformer is an architecture that allows LLMS to understand text context by processing data in parallel.
It is a deep learning architecture that relies on the parallel multi-head attention mechanism. The modern Transformer was proposed in the 2017 paper titled ‘Attention Is All You Need’ by Ashish Vaswani et al, Google Brain team.
Transforming word vectors into word predictions
GPT-3, a 2020 predecessor to the language models that power ChatGPT, is organized into dozens of layers. Each layer takes a sequence of vectors as inputs—one vector for each word in the input text—and adds information to help clarify the meaning of that word and better predict which word might come next.
Let’s start by looking at a stylized example:

{kind=link}
Each layer of an LLM is a transformer, a neural network architecture that was first introduced by Google in a landmark 2017 paper.
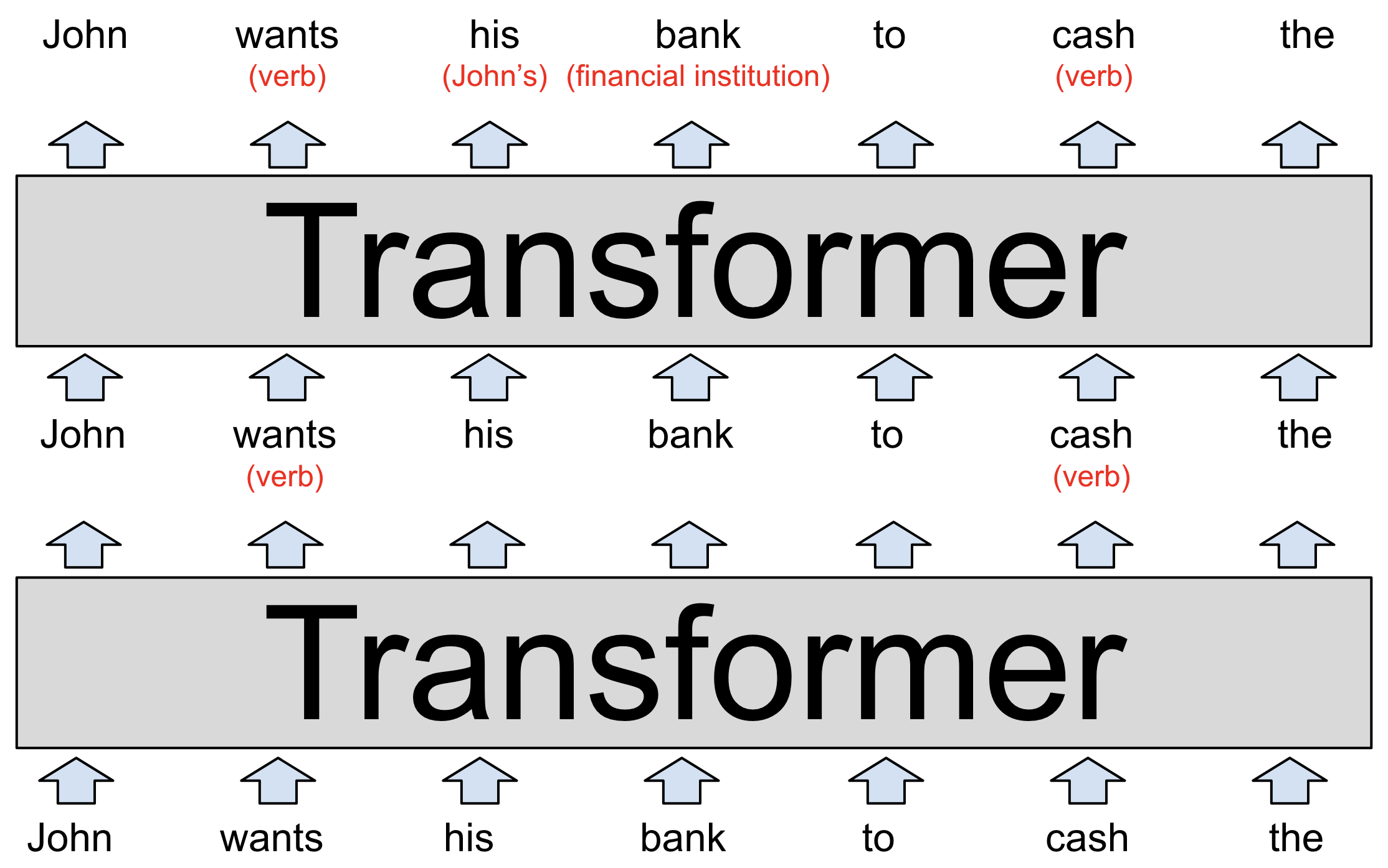
The model’s input, shown at the bottom of the diagram, is the partial sentence “John wants his bank to cash the.” These words, represented as word2vec-style vectors, are fed into the first transformer.
The transformer figures out that wants and cash are both verbs (both words can also be nouns). We’ve represented this added context as red text in parentheses, but in reality, the model would store it by modifying the word vectors in ways that are difficult for humans to interpret. These new vectors, known as a hidden state, are passed to the next transformer in the stack.
The second transformer adds two other bits of context: It clarifies that “bank” refers to a financial institution rather than a river bank, and that “his” is a pronoun that refers to John. The second transformer produces another set of hidden state vectors that reflect everything the model has learned up to that point.
The above diagram depicts a purely hypothetical LLM, so don’t take the details too seriously. We’ll take a look at research into real language models shortly. Real LLMs tend to have a lot more than two layers. The most powerful version of GPT-3, for example, has 96 layers.
« Back to Glossary Index